MiniNeo: A Simplified Learned Query Optimizer with Tree Convolution
- PostgreSQL's optimizer gets complex joins wrong
- trained a tree convolution network to learn from actual execution feedback instead
- beats PostgreSQL on the Join Order Benchmark by 1.2x
- no hand-tuned rules

The Problem with Traditional Query Optimization
Query optimization is the process of selecting the most efficient execution plan for a given SQL query. The optimizer must determine the join order, join algorithms, access methods, and other execution details. The space of possible execution plans grows exponentially with the number of joined tables, making exhaustive exploration impractical for complex queries.
Traditional query optimizers fall into two categories: rule-based and cost-based. Rule-based optimizers apply predetermined transformation rules. Cost-based optimizers estimate the cost of execution plans using statistics about the data. PostgreSQL uses a cost-based optimizer that combines heuristics with statistical estimates.
The fundamental challenge is cardinality estimation — predicting the number of records that will flow through each operator in the plan. Errors propagate and compound through the plan, leading to suboptimal execution strategies, especially for queries with complex predicates or multiple joins.
This is where traditional optimizers fall apart. The Join Order Benchmark (JOB) was specifically designed to expose this weakness — it runs 113 queries over the Internet Movie Database with complex multi-table joins, exactly the scenario where cardinality estimation errors compound into poor plans.
Learning from Execution, Not Estimates
Neo, introduced by Marcus et al. in 2019, took a different approach: instead of estimating cost, train a neural network to predict actual execution time, then use it to guide plan search. The system bootstraps from an existing optimizer and progressively improves through a feedback loop, learning from the actual performance of executed plans.
Neo's architecture is complex, handling join order selection, join algorithm selection, and index usage simultaneously. MiniNeo narrows the scope to join order optimization specifically. This simplification makes the architecture manageable while preserving the core learning mechanism: tree convolution to process query plan trees, a value network to predict execution times, and a feedback loop for continuous improvement.
MiniNeo learns from query execution feedback, building a value network that predicts the execution time of partial and complete query plans. This value network guides a best-first search algorithm to explore possible join orders. Through iterative training on a representative query workload, MiniNeo progressively improves its ability to identify efficient join orders.
System Architecture
MiniNeo operates in two phases. The initial phase collects expertise from PostgreSQL — execution plans and their actual runtimes serve as the starting point for training the value network. The runtime phase uses the trained value network to guide a best-first search for efficient execution plans, executing selected plans and feeding results back into training.
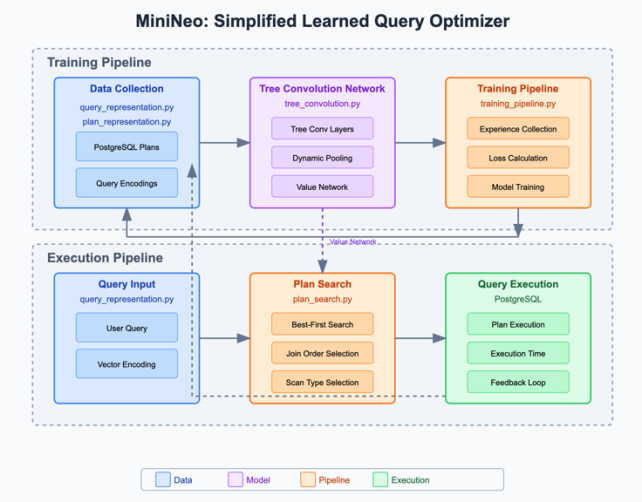
Figure 1: MiniNeo system architecture. The training pipeline (top) collects data from PostgreSQL and trains the tree convolution network. The execution pipeline (bottom) takes a user query through plan search and execution with a feedback loop.
The system has four main components:
Query and plan representation. Queries and plans are encoded as vectors the neural network can process. The query representation captures two aspects: a join graph encoded as an adjacency matrix indicating which tables are joined together, and predicate information encoded as a one-hot vector indicating which columns have predicates. The plan representation preserves the tree structure of execution plans, with each node encoded as a vector — join nodes encode the join type and tables involved, scan nodes encode the table being scanned and the scan method (table scan or index scan).
Tree convolution network. The core learning component processes query execution plans. The network architecture consists of a query encoder (a fully connected network for query-level features), three layers of tree convolution that process the plan tree structure, a dynamic pooling operation that produces a fixed-size vector from the variable-sized tree, and final fully connected layers that predict execution time.
The tree convolution operation is particularly suited for query plans because it captures local patterns in the tree structure. Each filter consists of three weight vectors for the parent node and its left and right children, applied to each "triangle" in the tree. This captures patterns like inefficient join operator combinations or beneficial data access patterns that correlate with execution performance.
Plan search algorithm. The search begins with unspecified scans for each table and progressively builds a complete plan by joining subtrees and specifying scan methods. At each step the algorithm generates child plans by applying join operators or specifying scan methods, evaluates each using the value network, and explores the most promising plan. The search is bounded by a 250ms time limit — if it's hit before a complete plan is found, the algorithm greedily completes the most promising partial plan.
Training pipeline. The pipeline collects initial experiences from PostgreSQL, trains the value network on collected experiences, uses the network to generate plans for queries, executes the plans and collects their actual execution times, adds new experiences to training data, retrains the network, and repeats. Starting with PostgreSQL's plans avoids the cold-start problem common in reinforcement learning.
Experimental Setup
I evaluated MiniNeo on the Join Order Benchmark (JOB), which consists of 113 queries over the Internet Movie Database. JOB is specifically designed to test query optimizers with complex join queries over real-world data — the queries involve between 4 and 17 table joins, exactly where cardinality estimation errors compound.
My implementation used PostgreSQL 14.0 as both the baseline optimizer and the execution engine, running on an Apple M1 Pro with 32GB of RAM. The neural network was implemented in PyTorch. I trained MiniNeo for 20 iterations. In each iteration, MiniNeo generated plans for all queries using the current value network, executed the plans, and retrained the value network with the accumulated experience (100 epochs, batch size 16, learning rate 0.001).
Performance Results
The results show consistent improvement across training iterations, with some variation in learning dynamics between runs.
Arithmetic mean speedup peaks dramatically at over 6x around iteration 5, while geometric mean speedup is more modest at around 1.3x. MiniNeo discovers highly efficient plans for certain queries early, though these extreme improvements aren't consistently maintained throughout training.
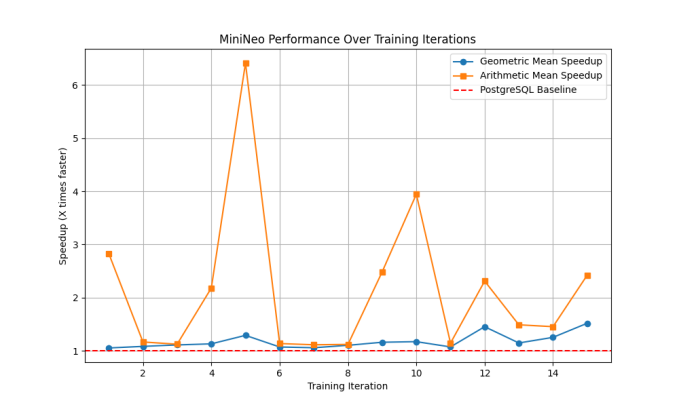
Figure 2
Consistency vs. magnitude. The geometric mean speedup generally shows more stable behavior than the arithmetic mean, suggesting that while MiniNeo achieves dramatic improvements for some queries, overall performance improvements are more modest but consistent.
Learning progression. Despite running in identical environments, each training instance shows distinct learning patterns. This variability is inherent to learned optimization approaches and demonstrates MiniNeo's ability to explore different regions of the solution space.
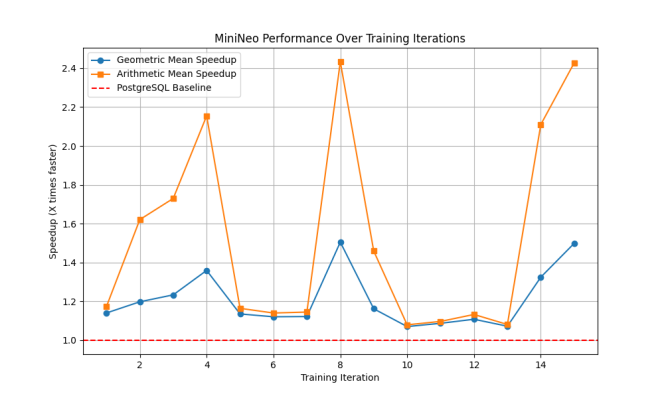
Figure 3
A more stable learning curve where both arithmetic and geometric mean speedups follow similar patterns. Performance improvements are more moderate but consistent, with arithmetic mean speedup stabilizing around 2.4x and geometric mean around 1.5x by iteration 14.
Performance steadily improves until iteration 10, reaching peaks of 2.6x arithmetic mean and 1.7x geometric mean, before a sharp decline. This pattern suggests MiniNeo can sometimes overfit to certain query patterns and may require periodic retraining to maintain optimal performance.
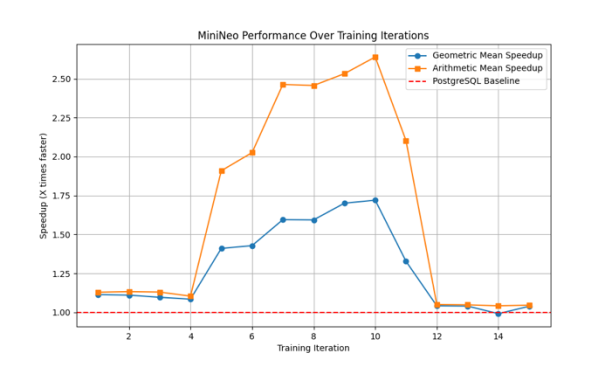
Figure 4
Baseline performance. Across all runs, MiniNeo maintains performance at or above the PostgreSQL baseline after the initial training period. The minimum geometric mean speedup across all runs is approximately 1.1x, indicating reliable improvement over traditional optimization.
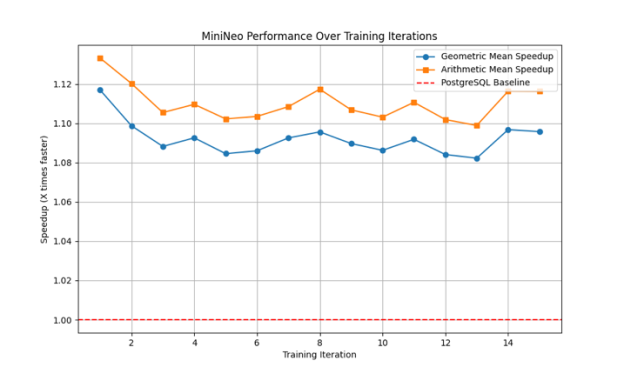
Figure 5
The most consistent performance pattern, with both metrics maintaining steady improvements between 1.08x and 1.13x throughout training. The stability of the performance gains suggests robust learning of generally applicable optimization strategies.
Late-stage discovery. Several runs show significant performance improvements in later iterations, suggesting that extended training periods can lead to the discovery of better optimization strategies.
A stable learning pattern with a sudden performance jump at iteration 14, where arithmetic mean speedup increases to 1.4x and geometric mean to 1.15x. MiniNeo can discover better optimization strategies even after extended training periods.
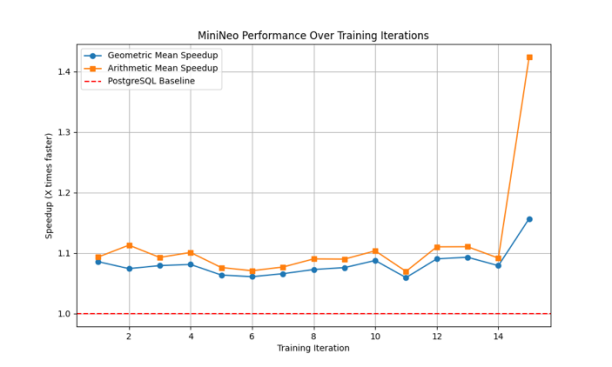
Figure 6
MiniNeo consistently outperforms the PostgreSQL optimizer after the initial training iterations. The geometric mean speedup stabilizes around 1.2x, indicating plans approximately 20% faster than PostgreSQL's on average. The arithmetic mean speedup shows higher variability but reaches up to 2.5x in some iterations, suggesting MiniNeo significantly improves performance for certain queries.
Analysis of Plan Choices
To understand how MiniNeo improves performance, I analyzed the plans it generates compared to PostgreSQL's plans.
MiniNeo often chooses different join orders than PostgreSQL, particularly for queries with many tables. For these complex queries, MiniNeo's learned join orders consistently outperform PostgreSQL's cost-estimated orders — which makes sense given that cardinality estimation errors are worst precisely in complex multi-join scenarios. MiniNeo also learns to select appropriate scan methods based on predicate selectivity and join context, and adapts its strategies to specific query patterns in the workload.
The performance improvements are particularly notable given that MiniNeo focuses only on join ordering, while PostgreSQL's optimizer addresses multiple aspects of query optimization. Winning on join order alone is meaningful.
Limitations
MiniNeo demonstrates the potential of learning-based query optimization but has real constraints.
Scope. MiniNeo addresses only join order optimization, not join algorithm selection or index usage. PostgreSQL's optimizer handles all of these; MiniNeo beats it on join ordering while ceding the other dimensions.
Training overhead. The iterative training process requires executing many query plans. For large workloads this is time-consuming — each of my 20 training iterations executed 113 queries, and each execution takes seconds on a complex join query.
Workload specificity. The current implementation learns from a specific workload and may not generalize well to very different query patterns. MiniNeo's improvements on JOB say something specifically about IMDB-scale complex join queries, not query optimization in general.
Query parsing. MiniNeo uses a simplified approach to extract query information that doesn't handle all SQL syntax correctly. Production deployment would require a more robust parser.
What I'd Do Next
Expanded optimization scope. Extending MiniNeo to handle join algorithm selection and index choice would address the dimensions it currently concedes to PostgreSQL, potentially compounding the improvements.
Better generalization. Techniques like transfer learning or more sample-efficient reinforcement learning could help MiniNeo generalize to unseen queries without requiring full retraining from scratch on each new workload.
Integration with database internals. The current approach uses PostgreSQL as a black box for execution. Deeper integration with the query execution engine — access to intermediate result statistics, operator-level profiling — could provide richer feedback signals for training.
Enhanced query representation. The current representation captures join graph and predicate information. More sophisticated representations could encode selectivity estimates, data distributions, or other features that correlate with execution performance.
The core result stands: a simplified learned optimizer using tree convolution and execution feedback can reliably beat a production cost-based optimizer on complex join queries, after only 20 training iterations bootstrapped from the optimizer it's replacing.